
Production-Ready GenAI Systems: Why Architecture Matters
In today's competitive landscape, the success of GenAI applications hinges on four critical factors: time to market, cost effectiveness, reliability, and system evolution. Organizations rushing to deploy generative AI solutions often discover that getting a model to produce impressive demos is vastly different from running a system that serves thousands of users without breaking the bank or breaking down. The difference between these two outcomes lies in architectural thinking.
In today's competitive landscape, the success of GenAI applications hinges on four critical factors: time to market, cost effectiveness, reliability, and system evolution. Organizations rushing to deploy generative AI solutions often discover that getting a model to produce impressive demos is vastly different from running a system that serves thousands of users without breaking the bank or breaking down. The difference between these two outcomes lies in architectural thinking.
Time to market accelerates when you build on solid architectural foundations. Rather than constantly firefighting production issues, teams can iterate quickly with confidence, knowing their infrastructure scales automatically and degrades gracefully under stress.
Cost effectiveness emerges from intelligent design choices—caching strategies that eliminate redundant API calls, smart routing that matches query complexity to model size, and dynamic resource allocation that prevents paying for idle GPU instances.
Reliability becomes achievable through resilient patterns: load balancing that distributes traffic, monitoring that catches issues before users do, and backup systems that ensure business continuity.
System evolution represents the long-term sustainability of your GenAI investment. The AI landscape changes rapidly—new models emerge monthly, user requirements shift, and business needs evolve. Architecture that supports seamless evolution allows organizations to adopt better models, integrate new capabilities, and adapt to changing requirements without costly rewrites. Systems designed for evolution become strategic assets that grow more valuable over time, rather than technical debt requiring constant replacement.
The journey from prototype to production-grade GenAI system requires understanding not just how to call an API, but how to architect systems that perform consistently at scale while managing operational costs, maintaining security, and evolving with the technology landscape. This article explores why architecture matters for GenAI systems and the practical patterns that separate successful deployments from expensive failures.
To achieve these four critical outcomes—rapid time to market, cost effectiveness, reliability, and evolutionary adaptability—organizations need a structured architectural framework. This is where the LGPL architecture emerges as a proven pattern for building production-ready GenAI systems.
Why Architecture Matters for GenAI Systems
Scalability Challenges
GenAI applications face unique scalability demands compared to traditional software. Large language models and generative systems require massive computational resources, handle unpredictable loads, and process complex requests. Without proper architecture, systems quickly become bottlenecks—slow response times, crashes under load, and unsustainable costs plague poorly designed implementations.
Real-World Impact: The LGPL Framework
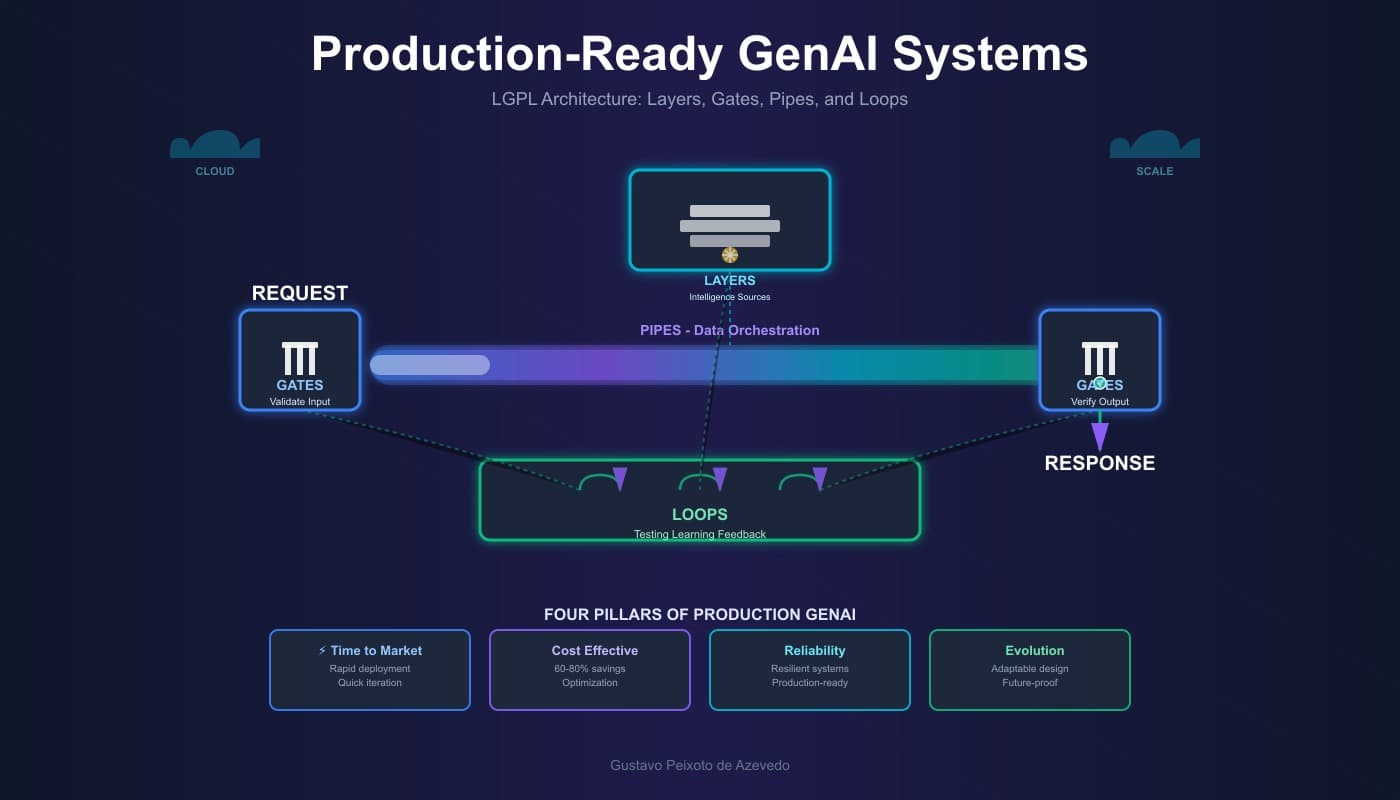
The LGPL architecture (Layers, Gates, Pipes, and Loops) emerged from Forrester Research's comprehensive study surveying the 15 largest service providers and their work with over 2,000 companies implementing GenAI-powered business applications. Introduced in their November 2023 report "Layers, Gates, Pipes, And Loops: A GenAI Application Architecture," this framework provides a structured approach for managing the complexity of GenAI systems.
Forrester's research revealed that the most advanced organizations achieve success through RAG-focused solution architectures where pipelines orchestrate data flow, gates provide governance and intent validation, and service layers integrate multiple intelligence sources. Critically, implementing intent gates on the input side and governance gates on the output side of generative models ensures both appropriate usage and safe, compliant responses.
The framework's components work synergistically: Gates control access and validate inputs, Pipes manage data flow between components, Layers integrate internal and external AI capabilities, and Loops enable iterative refinement—essential for applications like chatbots that need multiple reasoning steps or image generators that iteratively improve outputs.
Architectural Pillars for GenAI Systems
Infrastructure & Deployment
Containerization and microservices enable independent scaling of different AI components. For example, you can scale your inference service separately from your data preprocessing pipeline. This modular approach allows teams to optimize each component individually and deploy updates without affecting the entire system.
Load balancing distributes requests across multiple model instances, preventing any single server from becoming overwhelmed during peak usage. This ensures consistent response times even as demand fluctuates throughout the day or during viral marketing campaigns.
Cloud-native strategies allow dynamic resource allocation—spinning up GPU instances only when needed, significantly reducing operational costs. Rather than maintaining expensive infrastructure 24/7, systems can elastically respond to actual demand patterns.
Resilience & Reliability
Error handling and retry logic are crucial because AI models can fail unpredictably (token limits, context overflow, API timeouts). Robust systems anticipate these failures and handle them gracefully, ensuring users receive helpful error messages rather than cryptic stack traces.
Monitoring and logging help identify when models produce poor outputs, drift from expected behavior, or experience performance degradation. Early detection allows teams to intervene before issues impact user experience at scale.
Disaster recovery ensures business continuity—if your primary AI service fails, backup systems take over seamlessly. This redundancy is critical for applications where AI functionality is core to the business value proposition.
Security & Ethics
Security measures protect against prompt injection attacks, data leaks, and unauthorized access to AI models. As GenAI systems process sensitive user data and business information, implementing proper authentication, input validation, and data encryption becomes paramount.
Explainable AI (XAI) builds trust by showing how the system reaches decisions—critical for healthcare, finance, and legal applications where stakeholders need to understand the reasoning behind AI-generated recommendations.
Ethical AI considerations ensure systems don't perpetuate biases or cause harm. Architecture plays a role through content filtering layers, bias detection mechanisms, and human-in-the-loop workflows for sensitive decisions.
Cost Optimization
AI inference represents one of the largest operational expenses in GenAI systems, but proper architecture transforms cost management from a constraint into a competitive advantage. Unlike traditional software where costs are relatively fixed, GenAI systems face unique economic challenges driven by token-based pricing, GPU utilization, and context window management.
Managing the Context Window Tax
The "context window tax" can exponentially increase spending, especially in long, media-rich interactions where input tokens accumulate rapidly. Architecture that intelligently manages context—summarizing conversation history, pruning irrelevant information, and selectively including only necessary context—can reduce token consumption by 40-60% without degrading quality.
Intelligent Caching and Preprocessing
Caching common embeddings and frequently requested outputs eliminates redundant processing, while tokenization and preprocessing can be offloaded to cheaper CPU instances rather than expensive GPUs, trimming GPU hours by 20-35%. System prompts, which can consume hundreds of tokens per request, should be optimized and cached at the infrastructure level.
Strategic Model Selection
Model choice, not hardware, is the single biggest lever on GenAI spend—picking the smallest model that meets accuracy and latency targets dramatically reduces costs. Smart routing architectures that direct simple queries to lightweight models (7B parameters) and complex reasoning to larger models (70B+ parameters) optimize the cost-performance tradeoff. Costs can vary by 90% between model tiers—GPT-3.5 Turbo costs 90% less than GPT-4 Turbo for similar tasks.
Batch Processing and Request Optimization
Batching requests efficiently maximizes GPU utilization and can cut cost per token by approximately 30%, while load-aware batching that auto-tunes batch size when queue depth rises further optimizes throughput. For non-real-time use cases, batch inference with larger batch sizes provides substantial savings over synchronous processing.
Dynamic Resource Allocation
Multi-tenancy and elastic clusters turn idle capacity into useful throughput, with typical utilization jumping from 25% to 60% through GPU partitioning and namespace quotas. Architecture that forecasts token-per-second demand and scales just-in-time prevents paying for underutilized GPUs while maintaining service levels.
Output Token Economics
Output tokens cost three to five times more than input tokens because generating responses is far more computationally expensive than processing prompts. Systems should be architected to constrain output lengths appropriately, use structured output formats that minimize verbosity, and implement streaming responses that can be terminated early when sufficient information is provided.
Provisioned vs. On-Demand Pricing
For predictable, high-volume workloads, provisioned throughput models offer better economics than pay-per-token pricing. Architecture that segments predictable base load (provisioned) from variable spikes (on-demand) optimizes costs while maintaining responsiveness during traffic surges.
Compound Cost Savings
The compounding effect of these architectural choices is substantial. Organizations implementing comprehensive cost optimization across context management, caching, routing, and resource allocation typically achieve 60-80% cost reductions while maintaining or improving user experience—transforming GenAI from a cost center into an economically sustainable competitive advantage.
System Evolution & Future-Proofing
The GenAI landscape evolves at unprecedented speed, with new models, techniques, and capabilities emerging constantly. Architecture designed for evolution ensures your system remains competitive and valuable over time.
Model Flexibility & Abstraction
Well-architected systems abstract model interfaces, allowing you to swap or upgrade underlying models without rewriting application code. When GPT-5 or Claude 5 releases, systems with proper abstraction layers can test and adopt new models in hours rather than months. This model-agnostic approach prevents vendor lock-in and allows you to leverage the best model for each specific task as the landscape shifts.
Versioning & Safe Experimentation
Production architectures support running multiple model versions simultaneously. You can gradually roll out new models to a subset of users, compare performance metrics side-by-side, and rollback instantly if issues arise. This capability enables continuous improvement without risking system stability. Organizations can experiment with fine-tuned models, test new prompting strategies, or evaluate emerging techniques while maintaining business continuity.
Incremental Migration Paths
Rather than requiring big-bang replacements, evolutionary architectures enable incremental improvements. You might start with a simple prompt-based system, then add RAG capabilities, later introduce fine-tuned models for specific domains, and eventually implement multi-agent orchestration—all without discarding previous work. Each evolution builds on solid foundations rather than requiring complete rewrites.
Integration Readiness
As new AI capabilities emerge—whether multimodal models, advanced reasoning systems, or specialized tools—architectures designed for evolution can integrate them seamlessly. Proper service boundaries, clear interfaces, and modular design mean new capabilities become plug-and-play additions rather than architectural upheavals. When image generation, code execution, or tool-use capabilities become relevant, evolutionary systems incorporate them naturally.
Technical Debt Management
Architecture that supports evolution actively prevents technical debt accumulation. Clear separation of concerns means improvements in one area don't cascade into breaking changes throughout the system. Automated testing, CI/CD pipelines, and infrastructure-as-code ensure changes can be made confidently. Rather than systems degrading over time, well-architected GenAI applications become more capable and refined with each iteration.
Business Requirement Adaptation
User needs and business priorities shift. Architectures designed for evolution allow you to pivot quickly when market demands change. Whether adding new use cases, supporting different languages, or scaling to new customer segments, evolutionary systems adapt without requiring fundamental redesigns. This agility transforms your GenAI system from a point solution into a platform that grows with your organization.
The Strategic Advantage of Evolution
The ability to evolve separates temporary competitive advantages from sustained market leadership. Systems architected for change become assets that compound in value, continuously improving and adapting as both technology and business needs advance.
Practical Scenarios
Customer Service Chatbot
Without architectural knowledge, you might deploy a single model instance that crashes during high traffic periods. With proper architecture, you implement load balancing, caching for common questions, graceful degradation when the AI is unavailable, and monitoring to catch when responses become unhelpful. The result is a system that maintains service quality even during unexpected traffic spikes.
Content Generation Platform
Rather than processing every request synchronously, you design asynchronous pipelines with queues that smooth out traffic bursts. Implement rate limiting to manage costs, add content filtering layers for safety, and create feedback loops for continuous improvement. This architecture allows you to serve more users without proportionally increasing infrastructure costs.
Enterprise AI Integration
Enterprise environments demand mature operational practices. You need MLOps practices for versioning models, CI/CD pipelines for safe deployments, rollback capabilities when new models underperform, and integration with existing enterprise security and compliance frameworks. These systems must coexist with legacy infrastructure while meeting stringent governance requirements.
The Bottom Line
The difference between a GenAI demo and a production system lies in architectural thinking. Many developers can call an API and get a result, but building systems that deliver on all four critical pillars requires a comprehensive architectural approach.
Time to Market: Organizations that invest in proper architecture from the beginning accelerate their deployment velocity by avoiding costly refactoring later. Well-designed systems with clear abstractions, modular components, and automated deployment pipelines enable rapid iteration with confidence. Teams can focus on delivering business value rather than firefighting production issues.
Cost Effectiveness: Intelligent architectural choices drive dramatic cost reductions through context management, strategic model selection, caching, and dynamic resource allocation. Organizations implementing comprehensive cost optimization typically achieve 60-80% reductions while maintaining or improving user experience—transforming GenAI from an expensive experiment into an economically sustainable competitive advantage.
Reliability: Resilient architectures deliver consistent performance through load balancing that distributes traffic, monitoring that catches issues before users do, error handling that gracefully manages failures, and backup systems that ensure business continuity. Production-grade systems handle unexpected loads, model failures, and edge cases without compromising user experience.
System Evolution: Perhaps most critically, architectures designed for change become strategic assets that grow more valuable over time. The ability to adopt new models in hours rather than months, integrate emerging capabilities seamlessly, and adapt to shifting business requirements separates temporary competitive advantages from sustained market leadership.
The path to production-grade GenAI systems requires bridging the gap between "getting AI to work" and "getting AI to work reliably at scale in production." Success comes from understanding not just the capabilities of generative models, but the architectural patterns—embodied in frameworks like LGPL—that make those capabilities valuable in real-world applications, today and tomorrow.
Systems that achieve all four pillars don't just perform better—they create compounding advantages. Fast deployment enables rapid learning. Cost efficiency enables scale. Reliability builds trust. Evolution sustains competitive advantage. Together, these pillars determine whether your GenAI project becomes a transformative success or an expensive failure.